SQL的執行順序一直學不明白?相信許多人都會有這樣的困擾。
今天數據君就用圖解的方式,手把手帶你理解SQL的執行順序,以及一些執行過程中的注意事項,希望能給大家一些幫助。
這是一條標準的查詢語句: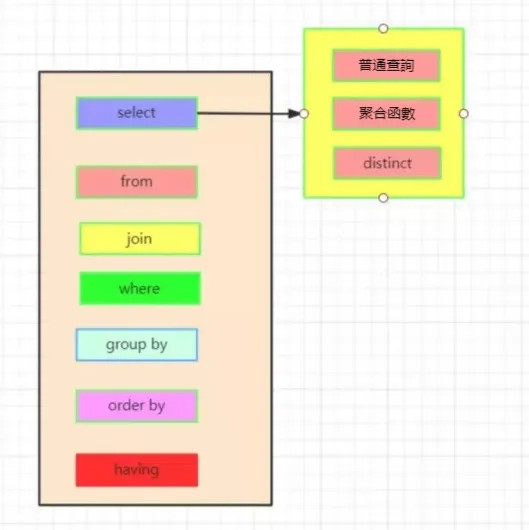
這是我們實際上的SQL執行順序:
●我們先執行from,join來確定表之間的連線關係,得到初步的數據
●where對數據進行普通的初步的篩選
●group by分組
●各組分別執行having中的普通篩選或者聚合函式篩選
●然後把再根據我們要的數據進行select,可以是普通欄位查詢也可以是獲取聚合函式的查詢結果,如果是集合函式,select的查詢結果會****新增一條欄位**
●將查詢結果去重distinct
●最後合併各組的查詢結果,按照order by的條件進行排序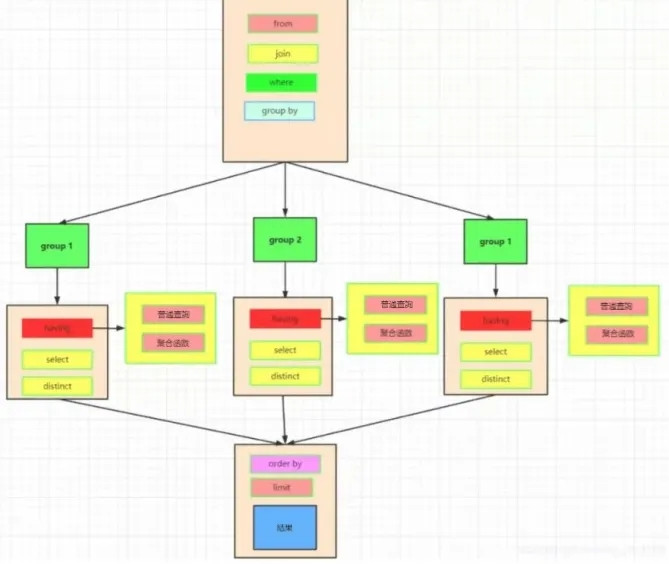
我們在理解SELECT語法的時候,還需要了解SELECT執行時的底層原理。只有這樣,才能讓我們對SQL有更深刻的認識。
其中你需要記住SELECT查詢時的兩個順序
●關鍵字的順序是不能顛倒的
●SELECT語句的執行順序(在MySQL和Oracle中,SELECT執行順序基本相同)
比如你寫了一個SQL語句,那麼它的關鍵字順序和執行順序是下面這樣的:
在SELECT語句執行這些步驟的時候,每個步驟都會產生一個虛擬表,然後將這個虛擬表傳入下一個步驟中作為輸入。
需要注意的是,這些步驟隱含在SQL的執行過程中,對我們來說是不可見的。
數據的關聯過程
數據庫中的兩張表: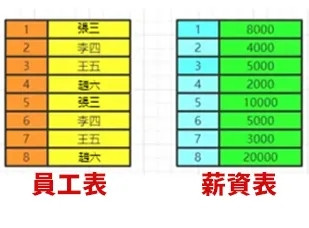
◆from&join&where
用於確定我們要查詢的表的範圍,涉及哪些表。
選擇一張表,然後用join連線
選擇多張表,用where做關聯條件
我們會得到滿足關聯條件的兩張表的資料,不加關聯條件會出現笛卡爾積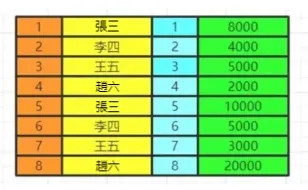
◆group by
按照我們的分組條件,將數據進行分組,但是不會篩選數據。
比如我們按照即id的奇偶分組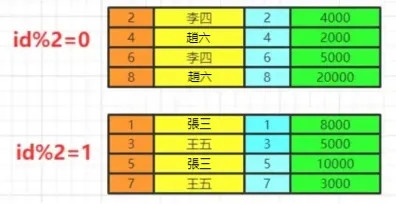
◆having&where
having中可以是普通條件的篩選,也能是聚合函式。而where只能是普通函式,一般情況下,有having可以不寫where,把where的篩選放在having裡,SQL語句看上去更絲滑。
●使用where再group by
先把不滿足where條件的數據刪除,再去分組。
●使用group by再having
先分組再刪除不滿足having條件的數據,這兩種方法有區別嗎,幾乎沒有!
舉個例子:
不同的是,having語法支援聚合函式,其實having的意思就是針對每組的條件進行篩選。
我們之前看到了普通的篩選條件是不影響的,但是having還支援聚合函式這是where無法實現的。
當前數據分組情況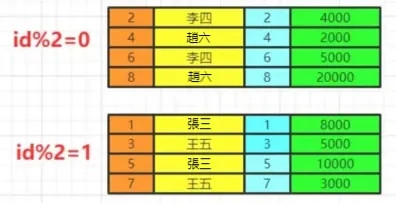
执行having的筛选条件,可以使用聚合函数。筛选掉工资小于各组平均工资的having salary<avg(salary)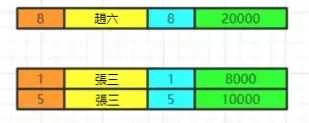
◆select
分組結束之後,我們再執行select語句。
因為聚合函式是依賴於分組的,聚合函式會單獨新增一個查詢出來的欄位,這裡用紫色表示。
這裡我們兩個id重複了,我們就保留一個id,重複欄位名需要指向來自哪張表,否則會出現唯一性問題。
最後按照使用者名稱去重

將各組having之後的數據再合併數據
◆order by
最後我們執行order by 將數據按照一定順序排序,比如這裡按照id排序。
如果此時有limit那麼查詢到相應的我們需要的記錄數時,就不繼續往下查了。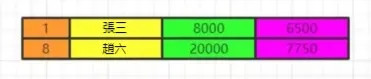
◆limit
記住limit是最後查詢的,為什麼呢?
假如我們要查詢年級最小的三個數據,如果在排序之前就擷取到3個數據。
實際上查詢出來的不是最小的三個數據而是前三個數據了,記住這一點。
我們如果limit0,3竊取前三個數據再排序,實際上最少工資的是2000,3000,4000。你這裡只能是4000,5000,8000了。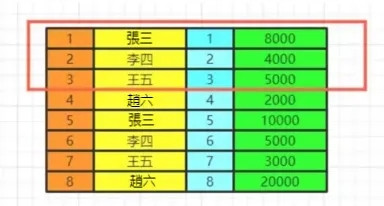
以上就是本期的內容分享~~,碼字不易,如果覺得對你有一點點幫助,歡迎「追蹤」,「按贊」,「分享」喔,我會持續為大家創作優質的內容~~
點選下方圖片免費體驗FineBI工具demo!
 groots
groots

